들어가기
이 포스팅은 개발자가 반드시 정복해야 할 객체 지향과 디자인 패턴를 읽고 수개월, 혹은 수년 뒤에 다시 이 글을 읽고 있을 제 자신을 위해 쓰여졌습니다. 다른 분들은 개념을 정리하는 차원에서 읽어주시면 감사하겠습니다. 글 쓰는게 익숙하지 않아 서투른 부분이 많은데, 코멘트는 언제나 환영입니다.
지저분한 코드

개발을 어느 정도 하다 보면 흔히들 스파게티 코드라고 하는 말을 어디선가 한번 쯤은 들어봤을 것이다. 코드가 분명히 동작은 하는것처럼 보이는데 사람이 읽고 그 내용을 파악하기가 어렵다면 이는 스파게티 코드일 가능성이 크다! 프로그램을 만들 때 구조적으로 고려하지 않았거나, 나중의 유지 보수는 무시한 채, 당장의 동작만을 염두하고 프로그램을 만들 경우 이런 스파게티 코드가 생겨날 수 있다.
이렇게 지저분한 코드를 짜면, 나중에 미래의 본인을 포함한 누군가가 고생을 하게 된다. 정말 간단한 유지 보수 혹은 아주 사소한 기능을 추가할 때에도 코드 전체를 파악해야 하고, 수정해야 하는 양 또한 증가한다. 시간에 쫓겨 급하게 코드를 짠 경우에야 어쩔 수 없지만, 그런 상황일지라도 최소한의 고민은 해보고 코드를 짜야 한다.
이러한 상황에 도달하지 않기 위해 다양한 프로그래밍 방법을 도입할 수 있다. 그 중에 하나로 가장 많이 쓰이는 객체 지향 프로그래밍에 대해 정리해보려고 한다.
그래서 객체 지향이 뭐야
객체 지향의 개념을 설명하면서 절차 지향을 그 반대의 예로 드는 것을 왕왕 볼 수 있는데 엄밀하게 말한다면 이는 틀렸다. 대부분의 프로그램은 데이터와 그 데이터를 조작하는 로직으로 구성되는데 절차지향의 경우는 데이터를 중심에 두고 프로시저들이 이 데이터들을 공유하는 모양으로 구성된다. 다수의 프로시져들이 데이터를 공유하기 때문에 절차 지향 프로그래밍은 데이터를 중심으로 구현하게 된다.
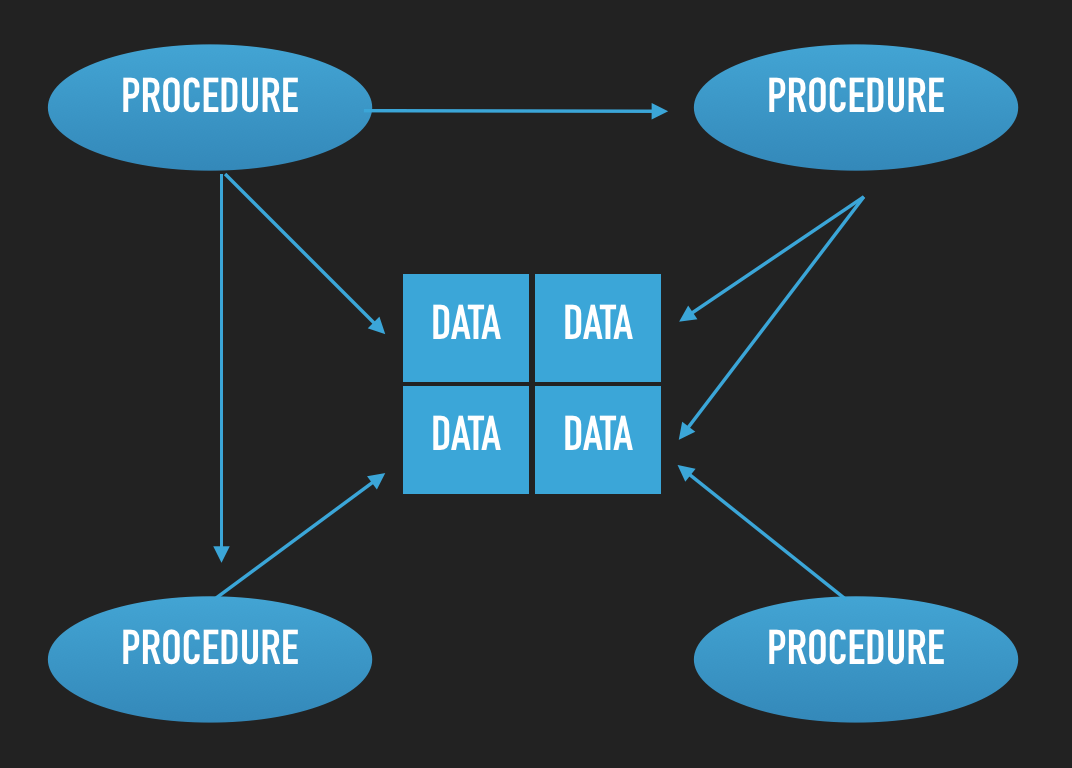
이렇게 절차지향적으로 코드를 작성하게 되면 초기에는 구현이 쉬워 빠르게 개발할 수 있지만, 규모가 커져서 데이터와 프로시져가 증가하면 문제점들이 발생한다. 데이터의 타입, 의미를 변경할 때, 함께 수정해야 하는 프로시져가 증가한다. 또 한명이 개발하는 경우가 아닌 여럿이 함게 개발하는 프로그램이라면, 같은 데이터를 프로시져들이 서로 다른 의미로 사용하는 경우가 발생할 수 있다.
반면에 객체지향에서는, 데이터와 이를 관리하는 프로시져를 객체라는 단위로 묶고 이들간의 네트워크로 프로그램을 구성한다.
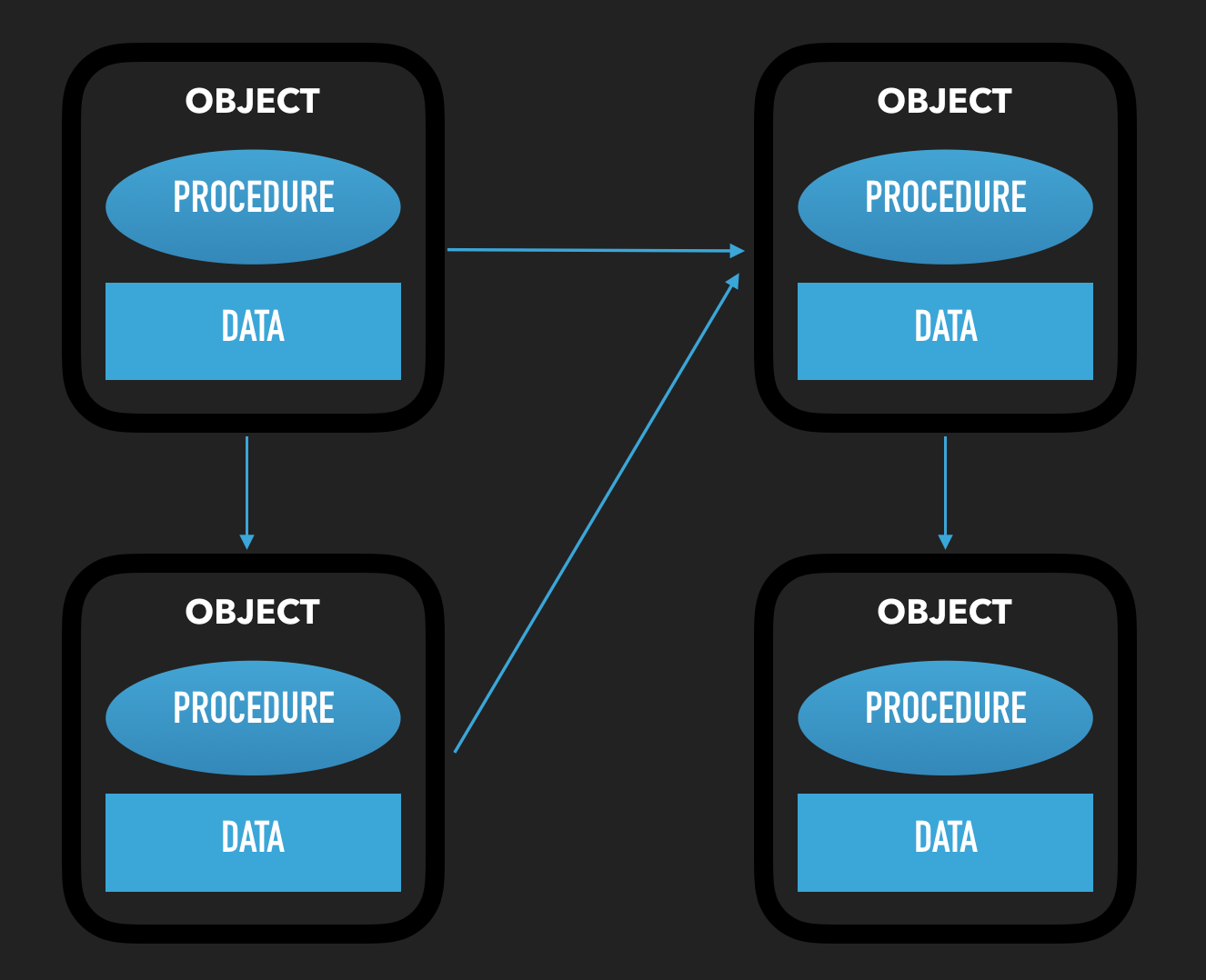
객체 지향의 핵심은 기능을 제공하는 것!
객체 지향의 핵심은 바로 기능을 제공해 준다는 것이다. 예를 들어 다음의 파이썬 코드를 살펴보자.
class Student():
def __init__(self, grade):
self.grade = grade
def get_grade(self):
return self.grade
위의 코드는 정말 간단한 Student라는 객체를 표현하고 있다. 이 때 다음의 두가지 경우를 생각해보자.
# CASE 1
student = Student(97)
print(student.grade) # 97
# CASE 2
student = User(97)
print(student.get_grade()) # 97
위의 두가지 경우는 Student 객체의 grade 이라는 값을 출력하고 있고 그 결과는 같다. 하지만 객체 지향적인 코드를 작성하기 위해서는 두번째 방법이 더 바람직 (실제로 파이썬에서는 getter와 setter를 사용하기보다는 property를 사용하는 편이 좀 더 적절하다.)하다고 할 수 있는데 그 이유를 살펴보자.
첫번째 경우는 Student 객체의 grade라는 데이터에 직접적으로 접근하고 있다. 이는 기능을 제공해준다는 객체 지향의 핵심에 어긋나는 행위로 볼 수 있다. 이와 반대로 두번째 경우는 Student 객체의 get_grade이라는 메서드를 통해서 원하는 동작을 수행하고 있다. 다시 말하면 Student 객체에 요구하고 있는 것이 첫번째의 경우는
“Student 객체의 grade”
두번째의 경우는
“Student 객체의 get_grade() 해줘”
이 둘 간의 미묘한 차이를 알겠는가? 객체 지향의 핵심은 (데이터가 아닌) 기능을 제공하는 것이다.
캡슐화
객체지향을 지탱하고 있는 중요한 개념들이 몇가지 있는데, 그 중 하나가 캡슐화다. 캡슐화 (encapsulation)는 객체가 내부적으로 기능을 어떻게 구현하는지를 감추는 것이다. 다시 말하면 어떤 객체를 사용하는 주체는 이 객체의 기능이 어떻게 구현되었는지를 알 필요가 없어야 한다는 것이다. 이를 통해 내부의 기능의 구현이 변경되더라도 그 기능을 사용하고 있는 코드는 영향을 받지 않게 된다.
객체 지향에 있어서 캡슐화의 중요도는 꽤나 크다. 하지만 객체 지향이라는 개념을 처음 접한 사람은 이를 적용하기가 쉽지 않다. 따라서 캡슐화를 위한 두개의 규칙을 소개해보려고 한다.
Tell, Don’t Ask
이 규칙은 말 그대로, 어떤 데이터를 요청하는 것이 아니라, 어떤 기능을 실행해달라고 요청하는 것이다. 앞선 Student 예제를 보면 쉽게 이해가 갈 것이다.
데이터를 읽는 것은 데이터를 중심으로 코드를 작성하게 만드는 원인이 되므로, 데이터 대신에 기능을 실행해달라고 명령을 내려야 한다.
데미테르의 법칙 (Law of Demeter)
앞선 “Tell, Don’t Ask” 규칙을 따를 수 있도록 만들어 주는 또 다른 규칙으로 다음의 규칙으로 구성된다.
- 메서드에서 생성한 객체의 메서드만 호출
- 파라미터로 받은 객체의 메서드만 호출
- 필드로 참조하는 객체의 메서드만 호출
데미테르의 법칙을 지키지 않았을 경우 전형적인 증상 두 가지는 다음과 같다.
- 연속된 get 메서드 호출
- 임시 변수의 get 호출이 많음
다형성과 추상화
다형성 (polymorphism)은 하나의 객체가 동시에 여러 가지 모습을 갖는다는 것이다. 여기서의 모습이라고 함은, 타입을 의미한다. 즉 하나의 객체가 동시에 여러 타입이 될 수도 있다는 것이다. 예를 들어 Person이라는 클래스를 상속받아 Student, Police 등등의 다양한 클래스들을 만들 수 있고, 이 때 Student 객체는 Person 타입인 동시에 Student 타입이라고 말할 수 있다. 여기서 Student는 Person 클래스가 제공하는 기능을 상속받아 사용, 구현 할 수 있다.
추상화(abstraction)는 데이터나 프로세스 등을 의미가 비슷한 개념이나 표현으로 정의하는 과정이다. 개인적인 이해로 추상화는 아래의 유명한 시와 느낌이 비슷하다.
내가 그의 이름을 불러주었을 때
그는 나에게로 와서
꽃이 되었다.
예를 들어, 다음의 코드는
sum = 0
for i in range(11):
sum += i
컴퓨터의 입장에서는 메모리 어딘가에 값을 저장하고 읽고 연산하는 행위에 불과하지만, 우리에게는 0부터 10까지의 합을 구하는 과정이다. 일종의 추상화라고 볼 수 있다. 저 sum이라는 값을 “0부터 10까지의 합” 이라고 추상화시킨것이다. 어떠한 새로운 객체의 개념을 정의해내는 것도 하나의 추상화하는 행위로 볼 수 있다.
SOLID 원칙
객체 지향을 가장 잘 설명하고 요약한 SOLID 원칙에 대해 알아보도록 하자.
1. 단일 책임 원칙 (Single responsibility principle)
하나의 클래스는 단 한 개의 책임(역할)을 가져야 한다
고 설명할 수 있는 아주 간단한 원칙이다. 혹은, 클래스를 변경하는 이유는 단 한 개여야 한다라고 표현하기도 한다.
여기서 말하는 책임이란 변화에 대한 것이다. 이 원칙이 지켜지지 않을 경우에 한 책임의 구현 변경에 의해 다른 책임과 관련된 코드가 변경될 가능성이 높아질 수 있다. 만약 클래스의 사용자들(다른 클래스)이 서로 다른 메서드들을 사용한다면 그들 메서드는 각각 다른 책임에 속할 가능성이 높고, 책임 분리 후보가 될 수 있다.
2. 개방 폐쇄 원칙 (Open-closed principle)
확장에는 열려 있어야 하고, 변경에는 닫혀 있어야 한다.
좀 더 풀어서 말하면, 기능을 변경하거나 확장할 수 있으면서 그 기능을 사용하는 코드는 수정하지 않아야 한다. 확장되는 부분(즉, 변화되는 부분)을 추상화해서 표현함으로 개방 폐쇄 원칙을 구현할 수 있다. 상속을 통해서도 개방 폐쇄 원칙을 구현할 수 있다. 상속되는 클래스의 메서드를 오버라이드 하면 된다. 클래스 B가 A를 상속받아서 구현이 됐다면 A의 기능을 확장하면서도 이와 동시에 A는 수정하지 않으므로 확장에는 열려 있으면서 변경에는 닫혀 있다고 말할 수 있는 것이다.
개방 폐쇄 원칙이 지켜지지 않을 경우에는 다음의 증상들이 나타난다.
- 다운 캐스팅을 한다.
- instanceof와 같은 타입 확인 연산자가 사용된다.
- 비슷한 if-else 블록이 존재한다.
개방 폐쇄 원칙은 변화되는 부분을 추상화함으로써 사용자(다른 클래스) 입장에서 변화를 고정시킨다. 상속을 통한 개방 폐쇄 원칙 구현에서도 변화되는 부분을 하위 클래스에서 오버라이딩 함으로써 기존 기능을 확장시킬 수 있었고, 하위 클래스에서 변경하더라도 상위 클래스는 변경할 필요가 없는 구조를 만들 수 있었다.
3. 리스코프 치환 원칙 (Liskov substitution principle)
리스코프 치환 원칙은 개방폐쇄 원칙을 받쳐 주는 다형성에 관한 원칙을 제공하는데, 다음과 같이 정의 할 수 있다.
상위 타입의 객체를 하위 타입의 객체로 치환해도 상위 타입을 사용하는 프로그램은 정상적으로 동작해야 한다.
리스코프 치환 원칙을 잘 지키면, 개념적으로는 상속 관계에 있는 것처럼 보일지라도 실제 구현으로는 상속 관계가 적합하지 않은 경우들을 판별해낼 수 있다.
타입을 확인하는 기능을 사용하는 것은 전형적인 리스코프 치환 원칙을 위반할 때 발생하는 증상이다. 클라이언트가 instanceof 연산자를 사용한다는 것은 상위 타입만을 사용해서 프로그래밍 할 수 없다는 것을 뜻하며, 이는 하위 타입이 상위 타입을 대체할 수 없다는 것을 의미한다. 이는 새로운 종류의 하위 타입이 생길 때마다 상위 타입을 사용하는 코드를 수정해줘야 할 가능성을 높이게 되고, 결국 개방 폐쇄 원칙을 지킬 수 없도록 만든다.
4. 인터페이스 분리 원칙 (Interface segregation principle)
간단하고 명료한 원칙이다.
인터페이스는 그 인터페이스를 사용하는 클라이언트를 기준으로 분리해야 한다.
용도에 맞게 인터페이스를 분리하는 것은 단일 책임 원칙과도 연결된다. 또 단일 책임 원칙이 잘 지켜지면 인터페이스와 콘크리트 클래스의 재사용 가능성을 높일 수 있다.
5. 의존 역전 원칙 (Dependency inversion principle)
고수준 모듈은 저수준 모듈의 구현에 의존해서는 안된다. 저수준 모듈이 고수준 모듈에서 정의한 추상 타입에 의존해야 한다.
고수준 모듈이 저수준 모듈을 사용하는 것으로 구현이 되어있는 경우, 고수준 모듈은 저수준 모듈에 의존하고 있다. 하지만 이렇게 구현할 경우, 저수준 모듈의 변경에 의해 고수준 모듈 또한 변경되어야 할 가능성이 커지게 된다. 따라서 저수준 모듈들을 추상화 시키고, 고수준 모듈이 이 저수준 모듈의 추상 타입에 의존하게 만들어 의존 관계를 역전시킨다. 이것이 바로 의존 역전 원칙이다.
객체 지향 설계 과정
객체 지향적 설계를 하는 과정은 다음과 같다.
- 프로그램의 필요한 기능을 나열한다.
- 각 기능들 중에서 요구하는 데이터가 겹치는 경우 이 기능들과 데이터를 묶는다.
- 앞선 원칙에 따라 2의 객체들을 적절히 분리, 추상화를 시킨다.
마무으리
객체지향을 적용할 때에는 여러가지 장점들이 있겠지만, 필자가 생각하기에 가장 중요하다고 느끼는 것은, 중복되는 부분을 줄일 수 있다는 것이다. 중복되는 부분을 줄임으로써 유지 보수를 함에 있어 반복되는 작업을 줄일 수 있고, 객체간의 역할과 책임을 분명하게 하여 사람이 이해하기 쉬운 코드를 쓰게 해준다는 것이다. 물론 프로그램의 복잡도가 증가한다는 단점도 있다.
참고
최범균. 개발자가 반드시 정복해야 할 객체 지향과 디자인 패턴. 인투북스 2013