들어가며
원글 Web Architecture 101의 내용이 좋아 확실한 기록을 위해 번역을 남겨두려 합니다. web 개발을 막 시작하시는 분들에게 도움이 되었으면 합니다. 피드백은 언제나 환영입니다.
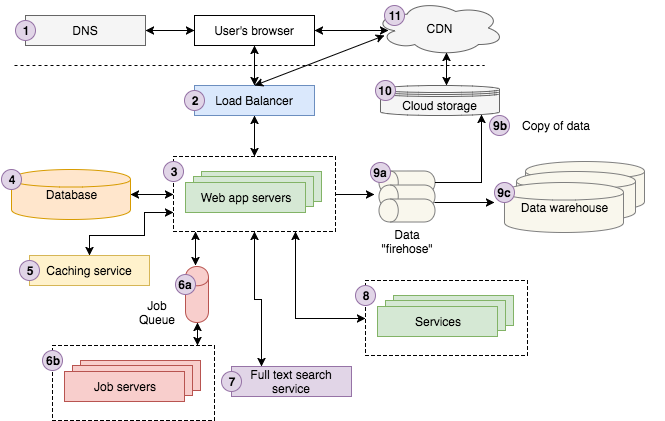
위 그림은 Storyblocks(원글의 저자가 개발하는 서비스로 추정)에서 사용하는 아키텍쳐를 꽤나 잘 나타내고 있다. 숙련된 웹 개발자가 아니라면 약간 복잡해보일 수도 있다. 각 컴포넌트를 살펴보기 전에, 다음의 글을 통해 좀 더 쉽게 다가가보자.
한 사용자가 구글에 다음과 같이 검색한다. “Strong Beautiful Fog And Sunbeams In The Forest”. 첫번째 나오는 결과는 우리 Storyblocks에서 제공한다. 사용자는 결과를 클릭하고 브라우저는 이미지 상세 페이지로 redirect 시킨다. 보이지 않는 곳에서 브라우저는 DNS 서버에 요청을 보내고 Storyblocks의 주소를 찾고 그 주소로 요청을 날린다.
요청은 load balancer에 도달한다. load balancer는 해당 요청을 처리할 수 있는 여러 web server 중에서 임의로 하나를 선택한다. web server는 caching service에서 이미지와 관련한 정보를 찾고 database에서 나머지 정보를 찾는다. 이미지의 color profile이 아직 계산되지 않았다. 그래서 “color profile” job을 job queue에 넣는다. 이 job server는 비동기적으로 database에 적절한 값을 업데이트 한다.
다음으로, 사진의 제목을 input으로 full text search service에 유사한 이미지를 찾도록 요청한다. 사용자는 StoryBlocks 에 회원으로 로그인 한 상태이기 때문에, account service에서 그의 계정 정보를 조회한다. 마지막으로, cloud system에 기록하기 위해 page view event를 data firehose에 발생시킨다. 결국에 분석가들이 business에 도움이 되는 정보를 얻는데 이용할 수 있도록 data warehouse에까지 저장한다.
server는 html 형식으로 render하고 load balancer를 통과하여 사용자의 브라우저에 돌려준다. 페이지는 Javascript와 CSS assets을 포함한다. 이 assets들은 cloud system에 올라가 있으며, CDN과 연결되어 있다. 사용자의 브라우저는 이 assets들을 CDN을 통해 얻는다. 이제 브라우저는 사용자가 볼 수 있도록 page를 render한다.
이제 각 컴포넌트들을 살펴보도록 하자. 웹 아키텍쳐 전반에 걸친 mental model을 구축할 수 있도록 “101”이라는 컨셉에 맞게 각 컴포넌트를 소개할 것이다. Storyblocks에서 배운 것들을 토대로 실제 구현의 조언들과 함께 일련의 글들을 계속 연재하려고 한다.
1. DNS
DNS는 “Domain Name System”의 약자이며 world wide web을 가능하게 해주는 중요한 기술이다. 가장 기본적인 DNS는 domain 이름(e.g., google.com)과 IP 주소(e.g., 85.129.83.120)를 매핑하는 key/value lookup을 제공한다. 사용자의 컴퓨터가 올바른 서버에 요청을 할 수 있도록 하는데 필요하다. 전화번호와 유사하다. “John Doe에게 전화해줘”는 “010-1234-5678로 전화해줘”인 것처럼 domain 이름과 IP 주소 사이의 관계도 그러하다. 옛날에 John의 전화번호를 찾기위해 전화번호부를 찾아봤던 것처럼 DNS를 찾아보는 것이다. domain과 IP 주소를 위한 전화번호부인 셈이다.
실제로는 더 많은 내용들이 있지만, 우리의 101-level에서는 중요하지 않으므로 넘어가도록 하자.
2. Load Balancer
load balancing을 자세히 살펴보기 전에, horizontal vs vertical application scaling에 대해 먼저 알아보자. 이 둘은 무엇이며 어떤 차이가 있을까? 간단히 이 StackOverflow 글에 따르면, horizontal scaling은 resource pool에 기기를 추가하는 것이고, vertical scaling은 기존 기기의 사양을 높이는 것이다. (e.g., CPU, RAM)
웹 개발에서, 거의 항상 horizontal scaling을 선호한다. 왜냐하면 기기는 고장나기 때문이다. 서버는 예기치 못하게 고장나고, 네트워크는 성능이 떨어지고, 데이터 센터는 종종 다운된다. 하나 이상의 서버를 갖는 것은 비상 상황을 대비할 수 있도록 해준다. 다시 말해 app이 “falut tolerant”하게 된다. 두번째, horizontal scaling은 각기 다른 서버에서 구동함으로서 다른 backend 서비스들(web server, database, service X, etc.)과의 커플링을 줄여준다. 또, vertical로는 scale에 한계가 있다. App이 필요로 하는 연산을 수행하기에 충분히 큰 컴퓨터가 이 세상에 없을 수도 있다. 구글의 검색 플랫폼을 생각해보아라. 심지어 더 작은 회사들에도 마찬가지다. 예를 들어, Storyblocks는 현재 150개에서 400개의 AWS EC2 instance를 구동하고 있다. 이 컴퓨팅 파워를 vertical scaling으로 제공하는 것은 무척 어려울 것이다.
이제 다시 load balancer로 돌아와서 load balancer는 horizontal scaling을 가능하게 해주는 마법소스다. load balancer는 들어오는 요청들을 여러 application servers(대개는 clone이나 mirror image) 중 하나로 전달하고, client에게 응답을 반환한다. 서버들은 모두 요청을 동일하게 처리한다. 중요한 것은 요청을 적절히 분배하여 하나의 서버가 과부하되도록 하지 않는 것이다.
이게 전부다. 개념적으로 load balancer는 상당히 간단하다. 그 내부는 좀 더 복잡하지만, 우리의 101 version에서는 몰라도 된다.
3. Web Application Servers
고수준의 web application servers는 상대적으로 설명하기가 쉽다. 사용자의 요청을 받아 핵심 비지니스 로직을 실행하고 사용자의 브라우저에 HTML을 돌려준다. 이 일을 하기 위해, databases, caching layers, job queues, search services, other microservices, data/logging queues 등과 같은 다른 다양한 backend 인프라들과 통신한다. 앞서 언급햇듯이, 아마 여러개의 application servers를 갖고, load balancer에 연결되어 있을 것이다.
app server를 구현하기 위해서는 특정한 언어(Node.js, Ruby, PHP, Scala, Java, C# .NET, etc.)와 그 언어에 맞는 web MVC 프레임워크(Express for Node.js, Ruby on Rails, Play for Scala, Laravel for PHP, etc.)를 필요로 한다. 그러나 이러한 언어와 프레임워크를 살펴보는 것은 이 글의 범위를 벗어난다.
4. Database Servers
모든 모던 web application은 하나 혹은 이상의 databse를 활용하여 정보를 저장한다.. Database는 data structure를 정의하고, 새로운 data를 삽입하고, 정보들을 검색하고 업데이트하고 삭제하고 그 이상의 것들을 한다. 대부분의 경우에 web app servers는 database와 직접 통신한다. 추가로, 각 backend 서비스는 다른 것들과 독립된 각각의 개별 database를 갖고 있을 것이다.
필자가 각 컴포넌트의 특정한 기술을 살펴보는 것을 피하고 있지만, database에서 SQL과 NoSQL을 이야기 하지 않는 것은 죄악이라고 생각하기 때문에, 이에 대해 얘기하려 한다.
SQL은 “Structured Query Language”의 약자이다. 1970년대에 개발되어 관계형 data set을 검색하는 표준적인 방법을 제공한다. SQL database는 table에 정보를 저장하며, table들은 common Ids(보통 integer)를 통해 서로 연결된다. 사용자의 주소 정보 이력을 관리하는 간단한 예시를 살펴보자. 두개의 table이 존재한다. users와 user_addresses, 이 둘은 user’s id를 기준으로 서로 연결된다. 아래의 이미지를 보자. tables은 연결되어 있다. 왜냐하면 user_addresses table의 user_id column이 “foregign key”로 users table의 id column을 참조하기 때문이다.
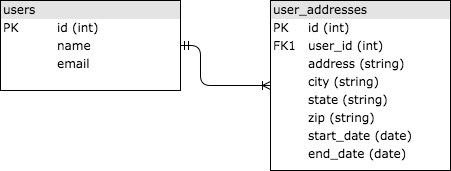
만약 SQL에 대해 잘 모른다면, Khan Academy와 같은 곳에서 tutorial을 하는 것을 강력히 추천한다. 웹 개발에 있어서는 기본이기 때문에, application의 적절한 구조를 짜고 싶다면 꼭 알아야 한다.
NoSQL은 “Non-SQL”의 약자다. 거대한 규모의 data를 다루기 위해 새로 등장한 database의 한 종류이다. (대부분의 SQL은 horizontal scaling이 어렵다). NoSQL에 대해 전혀 모른다면, 아래의 글들을 추천한다.
- https://www.w3resource.com/mongodb/nosql.php
- http://www.kdnuggets.com/2016/07/seven-steps-understanding-nosql-databases.html
- https://resources.mongodb.com/getting-started-with-mongodb/back-to-basics-1-introduction-to-nosql
NoSQL database를 위한 interface 조차도 SQL로 이루어지기 때문에, SQL에 대해 모른다면 반드시 배워야 한다. SQL은 피할 수 없다.
5. Caching Service
caching service는 거의 O(1) 시간안에 찾아볼 수 있는 key/value data store를 제공한다. 대개 application은 caching service를 비싼 연산의 결과 저장에 활용한다. 같은 결과를 필요로 할 때 재연산하는 것이 아니라, cache에서 빠르게 결과를 찾아온다. application은 database query의 결과, HTML과 같은 외부 서비스 호출을 cache한다. 다음은 실제 예시다:
- Google은 “dog”, “Taylor Swift”와 같은 흔한 검색에 대한 결과를 매번 계산하지 않고, cache해둔다.
- Facebook은 post data, 친구 목록 등과 같이 로그인 했을 때 보여지는 많은 정보들을 cache한다. 자세한 내용은 다음을 참고하라.
- Storyblocks는 server-side React rendering의 결과 HTML, 검색 결과, 자동완성 결과 등을 cache한다.
가장 많이 쓰이는 caching server 기술은 Redis와 Memcache다. 다른 posting에서 자세히 다뤄보도록 한다.
6. Job Queue & Servers
대부분의 web application은 사용자의 요청에 즉각적으로 반응할 필요가 없는 비동기적인 일을 해야한다. 예를 들어, Google은 인터넷 전체를 수집하고 저장해야한다. 이러한 작업이 매 검색요청마다 이루어지는 것이 아니다. 대신에, 비동기적으로 수집하고, index를 업데이트한다.
이러한 비동기 작업을 가능하게 해주는 여러가지 아키텍쳐가 있지만, 가장 보편적인 경우는 “job queue”라 불리우는 구조다. 두개의 컴포넌트로 구성된다. “jobs”가 들어가는 queue와 이 job을 수행하는 하나 혹은 그 이상의 job servers (“workers”라고도 한다)다.
job queue는 비동기적으로 실행되어야 하는 job 목록을 저장한다. 가장 간단한 버전은 first-in-first-out (FIFO) queue이다. 대부분의 경우에는 priority queing system을 많이 사용한다. app이 정기적이든, 사용자의 요청에 의한 것이든 비동기적인 job을 실행시키고 싶을 때마다, 적당한 job을 queue에 넣는다.
예를 들어, Storyblocks는 marketplace 지원을 위해 job queue를 사용한다. 동영상과 사진의 인코딩, 메타데이터 태깅을 위한 csv 처리, 사용자 통계, 비밀번호 초기화 이메일 ㅂ라송, 등의 일들을 job queue를 통해 처리한다. 처음에는 간단한 FIFO queue를 사용했었으나, 비밀번호 초기화 이메일 발송과 같이 시간에 민감한 작업들을 처리하기 위해 priority queue를 도입했다.
job servers는 job을 수행한다. job queue를 폴링하고, 수행해야 할 job이 있는 경우에는 queue에서 job을 꺼내 실행한다. 언어와 프레임워크와 같이 실제 구성의 선택은 web servers 만큼 다양하기 때문에 자세한 내용은 여기서 다루지 않는다.
7. Full-text Search Service
사용자가 어떤 text input(query)를 입력하면 가장 “연관된” 결과를 반환하는 검색기능은 대부분은 아니지만 많은 서비스가 제공하는 기능이다. 이러한 기능을 가능하게 해주는 기술을 흔히 “full-text search“라고 부른다. inverted index를 활용하여 검색어를 포함하고 있는 문서들을 빠르게 검색한다.

database에서 직접 full-text search를 (e.g., MySQL은 full-text search를 지원한다) 하기도 하지만, 보통은 별도의 “search service”를 분리하여 inverted index를 계산, 저장하고 query interface를 제공한다. Sphinx 혹은 Apache Solr와 같은 서비스가 있지만 오늘날 가장 인기있는 full-text search 플랫폼은 Elasticsearch이다.
8. Services
app이 일정 수준에 도달하면, 쪼개서 별도의 분리된 application으로 제공해야 되는 서비스들이 있다. 외부 세상으로 노출되는 것은 아니지만 application이 통신한다. Storyblocks를 예시로 들면 다음의 별도의 서비스들이 진행중이거나 계획중이다.
- Account 서비스는 전 사이트에 걸쳐 사용자 정보를 저장하고, 사이트 전반에 걸친 판매 기회와 일관된 UX를 제공한다.
- Content 서비스는 동영상, 오디오, 이미지에 대한 metadata를 저장한다. 또한 content를 다운로드하거나 다운로드 이력을 조회하는 interface를 제공한다.
- Payment 서비스는 고객의 신용카드 결제를 위한 interface를 제공한다.
- HTML → PDF 서비스는 HTML를 PDF로 변환해주는 간단한 inteface를 제공한다.
9. Data
오늘날, 회사들은 얼마나 data를 잘 다루는가에 생사가 달렸다. 거의 요즘 모든 app들은, 어떤 수준에 도달하면, data 수집, 저장, 분석을 위해 data pipeline을 사용한다. 전형적으로 pipeline은 다음의 주요 3단계를 갖는다.
- app이 사용자 interaction에 관한 data를 data “firehose”에 전송한다. 이 data “firehose”에서는 data를 즉각적으로 처리할 수 있는 streaming interface를 제공한다. 보통 raw data는 변환되거나 정보가 추가되어 또 다른 firehose에 전달된다. AWS Kinesis나 Kafka는 이러한 목적을 위한 가장 흔한 두가지 기술이다.
- raw data와 변형/추가된 data는 cloud storage에 저장된다. AWS Kinesis는 “firehose”라고 불리는 설정을 제공하는데, 이를 이용하면 아주 간단하게 could storage (S3)에 저장할 수 있다.
- 변형/추가된 data는 분석을 위해 data warehouse에 올라간다. 스타트업 세계에서는 AWS Redshift를 사용하고, 좀 더 규모가 있는 회사에서는 Oracle이나 다른 warehouse 기술을 사용한다. data set이 충분히 큰 경우에는, 분석을 위해 Hadoop 같은 NoSQL MapReduce 기술을 사용하기도 한다.
위 그림에 나타나지 않은 또 다른 단계는 app과 서비스의 database에서 data warehouse로 로드하는 과정이다. 예를 들어 Storyblocks에서는 매일 밤마다 VideoBlocks, AudioBlocks, Storyblocks, account service, and contributor portal databases를 Redshift로 로드한다.
10. Cloud storage
AWS에 따르면 “Cloud storage는 Internet 상에서 data를 저장하고 접근하고 공유하는 간단하고도 scalable한 방법이다”. Cloud storage를 사용하면 HTTP 위에서 RESTful API를 통해 local 파일 시스템에 있는 파일들을 저장하고, 파일들에 접근할 수 있다. Amazon의 S3는 오늘날 가장 인기있는 cloud storage이고, Storyblocks에서도 동영상, 오디오, 사진, CSS, Javascript, 사용자 event data 등 많은 정보를 S3에 의존하고 있다.
11. CDN
CDN은 “Content Delivery Network”의 약자다. HTML, CSS, Javascript와 같은 정적 파일을 단일 origin server에서 하는 것보다 빠르게 제공하는 기술이다. content를 전세계에 있는 여러 “edge” 서버에 걸쳐서 분산하여 사용자들은 origin server가 아닌 “edge” 서버에서 다운로드 받는다. 예를 들어, 아래에 있는 이미지를 보자, 스페인에 있는 한 사용자가 뉴욕에 있는 origin server에 web page를 요청하지만, 정적 파일들은 느린 대서양 HTTP request가 아니라 영국에 있는 CDN “edge” 서버에서 빠르게 다운로드 받는다.
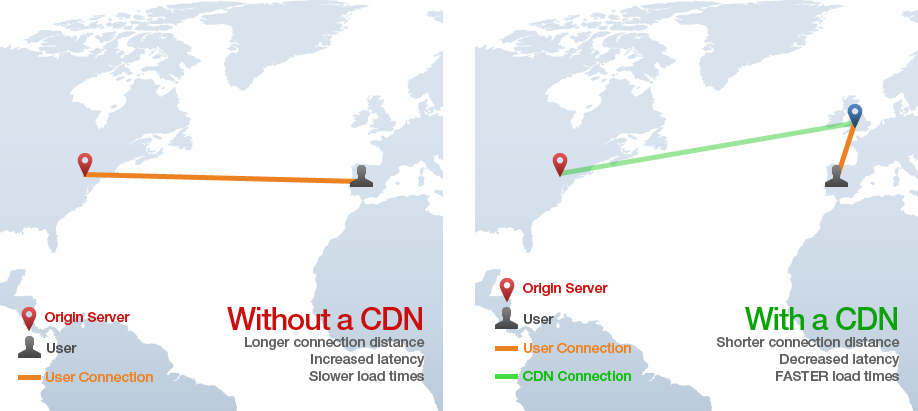
보통 web app은 CSS, Javascript, 이미지, 동영상 다른 assets들을 제공하기 위해 CDN을 사용한다. 어떤 app들은 정적인 HTML 파일을 제공하는데 사용하기도 한다.
마치며
지금까지 Web Architecture 101이었다. 이 글이 도움이 되었으면 좋겠다. 내년이나 내후년에 몇몇의 컴포넌트를 자세히 다루는 201 시리즈도 연재하고 싶다.