추천 시스템
요즘에 어떤 서비스를 보더라도 추천 시스템은 필수적인 요소로 자리를 잡았다고 해도 과언이 아니다. 대표적으로 넷플릭스, 아마존 에서는 추천 시스템을 기반으로 서비스를 운영하고 있고 추천 시스템이 이러한 서비스에 기여하는 바는 어마어마하다. (참고)
- Netflix : 대여되는 영화의 2/3가 추천으로부터 발생
- Google News : 38% 이상의 조회가 추천에 의해 발생
- Amazon : 판매의 35% 가 추천으로부터 발생
- Netflix Prize (~2009) Netflix에서 주관하는 경연대회로, 영화 선호도를 가장 잘 예측하는 협업 필터링 알고리즘에 수상 (US$1,000,000)
이렇게 중요한 추천시스템은 어떻게 동작하는가!
추천 시스템을 구현하는 방법에는 크게 두 가지가 있다. 협업 필터링 (Collaborative Filtering)과 내용 기반 (Content-based) 추천이다.
내용 기반(Content-based) 추천
말 그대로 컨텐츠 자체의 내용을 기반으로 비슷한 컨텐츠를 추천해준다. 예를 들어 사용자가 마블사의 영화를 봤다면, 이를 기반으로 마블사의 다른 영화를 추천해 줄 수 있다. 혹은 텍스트 기반의 컨텐츠에서는 TF-IDF와 같은 방법을 사용할 수도 있다. 이 글에서는 내용 기반 추천에 대해서는 자세히 다루지 않고 넘어가도록 한다.
협업 필터링 Collaborative Filtering
추천 시스템에서의 협업 필터링은 많은 유저들로부터 모은 취향 정보들을 기반으로 하여 스스로 예측하는 기술을 말한다. 협업 필터링은 어떤 특정한 인물 A가 한가지 이슈에 관해서 인물 B와 같은 의견을 갖는다면 다른 이슈에 대해서도 비슷한 의견을 가질 확률이 높을 것이라는 사실에 기반한다. 어떻게 보면 집단 지성 비슷한 것으로 이해하면 된다.
기본적으로 협업 필터링의 종류에는 Memory-based, Model-based, Hybrid 가 있지만 이중에서 간단하게 구현할 수 있으며, 적당히 합당한 결과를 도출하는 Memory-based 협업 필터링에 대해 알아보자.
Memory-based 협업 필터링의 추천 시스템은 유사도를 기반으로 동작한다. 사용자-사용자 간의 유사도를 기준으로 하는 경우는 사용자 기반(User-Based), 아이템-아이템 간의 유사도를 기준으로 하는 경우는 아이템 기반 (Item-Based)이다.
사용자 기반, 아이템 기반의 협업 필터링을 설명하기 앞서 간단한 예시 상황을 가정하도록 한다. 다음은 어떤 사용자들이 영화의 평점을 (0~5) 사이의 값으로 매긴 결과이다. 빈칸은 평가를 하지 않은 항목이다.
| 공조 | 더 킹 | 라라랜드 | 컨택트 | 너의 이름은 | |
|---|---|---|---|---|---|
| 재석 | 5 | 4 | 4 | 3 | |
| 명수 | 1 | 0 | 1 | 4 | |
| 하하 | 4 | 4 | 5 | 3 | |
| 준하 | 2 | 1 | 4 | 3 | |
| 세형 | 4 | 4 | 4 | 2 | |
| 광희 | 4 | 2 | 3 | 1 |
사용자 기반 (User-Based)
사용자 기반의 협업 필터링에서의 유사도는 두 사용자가 얼마나 유사한 항목(아이템)을 선호했는지를 기준으로 한다. 사용자 기반에서는 한 사용자가 평가한 영화들의 점수들을 벡터로 나타낼 수 있다. 위의 예시에서 재석의 평가 점수는 (5, 4, 4, 3, -)로 나타낼 수 있다. 이 때 두 사용자 간의 유사도는 두 벡터 간의 유사도로 정의할 수 있다. 두 벡터 간의 유사도를 구하기 위해서 다양한 방법이 사용될 수 있는데 대개는 코사인 유사도, 피어슨 유사도가 이용된다.
코사인 유사도를 이용해 명수와 준하의 유사도를 구해보자. 유사도를 구할 때에는 두 사용자가 공통으로 평가한 항목에 대해서만 계산한다. A=(0, 1, 4), B=(2, 1, 3)이고, 코사인 유사도는 다음과 같이 정의된다.
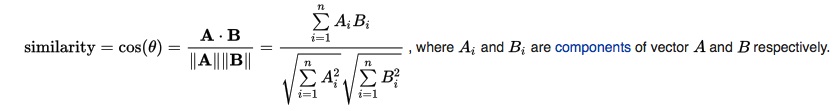
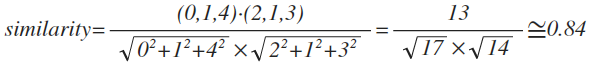
이런식으로 모든 사용자에 대해서 유사도를 구하면, 사용자 수 * 사용자 수 (6*6) 크기의 유사도 행렬을 만들 수 있다.
| 유사도 | 재석 | 명수 | 하하 | 준하 | 세형 | 광희 |
|---|---|---|---|---|---|---|
| 재석 | 1.00 | 0.84 | 0.96 | 0.82 | 0.98 | 0.98 |
| 명수 | 0.84 | 1.00 | 0.61 | 0.84 | 0.63 | 0.47 |
| 하하 | 0.96 | 0.61 | 1.00 | 0.97 | 0.99 | 0.92 |
| 준하 | 0.82 | 0.84 | 0.97 | 1.00 | 0.85 | 0.71 |
| 세형 | 0.98 | 0.63 | 0.99 | 0.85 | 1.00 | 0.98 |
| 광희 | 0.98 | 0.47 | 0.92 | 0.71 | 0.98 | 1.00 |
이때 세형의 더 킹에 대한 평가 점수를 예측해보고 싶다고 할 때, 우리는 여러 방법을 적용할 수 있다. 세형과 가장 유사한 몇명의 점수를 이용하여 예측 점수로 구할 수도 있고, 전체를 대상으로 유사도 기반의 weighted sum 값을 예측 점수로 사용할 수도 있다. 후자의 경우로 세형의 더 킹에 대한 평가 점수를 예측해보자.
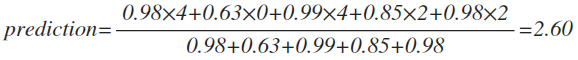
아이템 기반 (Item-Based)
아이템 기반도 앞선 사용자 기반과 매우 유사한 과정을 거친다. 다만 앞에서는 사용자에 대한 유사도를 계산했다면, 여기서는 아이템들에 대한 유사도를 계산한다. 마찬가지로 두 아이템에 대한 사용자들의 평가 점수를 벡터로 나타내보자. 공조와 라라랜드의 유사도를 구하려고 한다면, 이 둘을 모두 평가한 사용자는, 재석, 명수, 세형, 광희다. 각각 (5, 1, 4, 4)와 (4, 1, 4, 3)이다.
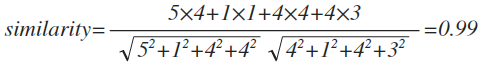
공조와 라라랜드의 유사도는 0.99로 상당히 높은 유사도를 보인다. 이는 즉 공조를 좋아하는 사람은 라라랜드를 좋아할 확률이 높다는 말로 풀이 될수 있고, 그 반대로도 해석할 수 있다.
아이템 기반에서도 앞에서 처럼 아이템 수 * 아이템 수 (5*5) 크기의 유사도 행렬을 만들 수 있다. 이를 기반으로 역시 예측 점수를 구할 수 있다.
고찰!?
앞서 유사도를 구하는 과정에서 코사인 유사도를 사용했는데, 만약 다음의 두 아이템의 유사도를 구해보자, (5, 5, 5, 5, 5, 5), (1, 1, 1, 1, 1, 1). 이 때, 이 둘간의 유사도는 1이다. 두 아이템에 대한 사용자들의 평가는 극명하게 갈리는데, 이 둘의 유사도가 1이라고 한다. 이렇게 코사인 유사도에서는 유저마다의 개인적인 평가 성향을 반영하지 못한다는 단점이 있다. 이를 보완하기 위해, 앞서 말한 피어슨 유사도, 혹은 약간의 보정 과정을 거친 코사인 유사도를 사용할 수도 있다.
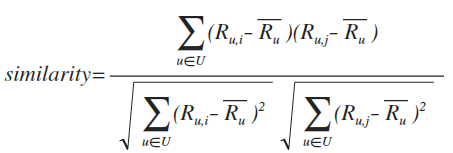
보정된 코사인 유사도에서는 사용자의 평균 평가 값을 빼줌으로써, 위의 문제를 어느 정도 해결할 수 있다.
사실 이 외에도 몇가지 문제점이 더 있다. 예를 들어, 어떤 두 아이템에 대해서 유사도를 구하려 하는데, 이 두 영화를 모두 평가한 사람이 한명뿐인 경우에 유사도가 역시 1이 나오게 된다. 이렇게 적은 데이터에 기반한 정보는 추천의 정확도를 떨어뜨릴 가능성이 높다. 이런 경우를 방지하기 위해 할 수 있는 조치는, 최소 평가 인원의 수를 정하는 것이다. 두 아이템을 모두 평가한 사람의 수가 5명 이상일 때부터 유사도를 계산하기로 하고, 5명 미만의 공통 평가 인원수를 갖는 두 아이템에 대한 유사도를 0으로 처리하는 것이다.
사용자 기반 vs 아이템 기반
결론부터 말하자면, 아마존과 넷플릭스를 비롯한 서비스에서는 대부분 아이템 기반을 활용한다고 알려져 있다. 또 적절한 UX를 위해서라면, 유저가 아이템을 평가하는 순간, 다른 아이템을 추천할 수 있어야 하는데, 매 평가시마다 유사도 정보를 업데이트하는 것은 현실적으로 어려울 것이다. 아이템 기반에서는 일정 기간마다 유사도를 업데이트 하는 것으로도 충분히 위와 같은 적절한 UX를 제공할 수 있다.
또 대부분의 경우는 사용자에 비해 아이템 수가 적기 때문에, 아이템 간의 관계 데이터가 발생할 확률이 높다. 따라서 데이터가 누적될수록 추천의 정확도가 높아질 가능성이 더 높다.
마무으리
나름 이것저것 조사하고 글을 정리했지만, 너무 얕은 지식으로 글을 썼기 때문에 적절하지 않은 내용이나 틀린 내용이 있을 수도 있다… (피드백을 주시면 최대한 반영하도록 하겠습니다.) 방대한 추천 시스템이라는 연구 분야에 살짝 발만 담가본 정도로 내용을 훑어 보았는데, 다음에 기회가 된다면, netflix prize 대회의 우승 논문을 살펴보도록 하겠다.
참고
추천 시스템 분석 – 어떻게 아마존과 넷플릭스가 당신의 취향을 예상하는가?
Item-base collaborative filtering
Item-Based Collaborative Filtering Recommendation Algorithms